Hướng tới Bác sĩ AI Tự động: So sánh Định lượng giữa AI Tự động và Bác sĩ Lâm sàng trong Bối cảnh Thực tế
Tác giả Hashim Hayat và cộng sự.
Nhóm Nghiên cứu Điện tử, New York, NY
Khoa Phẫu thuật, Đại học California, San Francisco, San Francisco, CA
Lực lượng lao động chăm sóc sức khỏe toàn cầu đang phải đối mặt với tình trạng thiếu hụt trầm trọng các nhà cung cấp dịch vụ. Theo một số ước tính, hiện cần thêm 4,3 triệu bác sĩ để đáp ứng nhu cầu về dịch vụ chăm sóc sức khỏe cơ bản trên toàn thế giới và mức thâm hụt này dự kiến sẽ lên tới 11 triệu vào năm 2030. Tổ chức Y tế Thế giới ước tính rằng 8 triệu người tử vong hàng năm do các bệnh có thể điều trị được. Chỉ riêng Hoa Kỳ dự kiến sẽ thiếu hụt 124.000 bác sĩ vào năm 2034, bao gồm 48.000 bác sĩ chăm sóc sức khỏe ban đầu và 77.000 bác sĩ chuyên khoa. Cuộc khủng hoảng này sẽ ngày càng trầm trọng hơn khi sự chuyển đổi nhân khẩu học thúc đẩy nhu cầu tăng trưởng theo cấp số nhân: dân số từ 65 tuổi trở lên trên toàn cầu sẽ tăng gấp ba lần vào năm 2050. Đồng thời, gánh nặng chăm sóc và ghi chép hồ sơ đã tăng lên. Gánh nặng hành chính chiếm 50% thời gian lâm sàng, khiến tỷ lệ kiệt sức lên tới hơn 45,8% ở tất cả các chuyên khoa. Các giải pháp truyền thống: mở rộng trường y, triển khai y tế từ xa và tối ưu hóa quy trình làm việc không thể thu hẹp khoảng cách này trong khung thời gian khả thi, vì đào tạo bác sĩ mất 11-15 năm và phải đối mặt với những hạn chế về tuyển sinh.
Các mô hình ngôn ngữ lớn (LLM), bao gồm các mô hình nền tảng, và các hệ thống AI tự động (giải pháp công nghệ đầu tiên có khả năng vượt qua giới hạn năng lực của con người trong việc ra quyết định và quản lý lâm sàng) có khả năng giải quyết cả những hạn chế về nguồn cung và nhu cầu ngày càng tăng. Với những tiến bộ trong xử lý ngôn ngữ tự nhiên và suy luận tạo sinh, LLM đã nhanh chóng phát triển từ các trợ lý tài liệu thành các tác nhân tinh vi có khả năng suy luận lâm sàng nhiều bước, chẩn đoán phân biệt và quản lý dựa trên bằng chứng.
Trong một thử nghiệm mù đôi, được đánh giá bởi chuyên gia, độ chính xác của chẩn đoán phân biệt và lập kế hoạch quản lý của tác nhân LLM y tế tự động Articulate Medical Intelligence Explorer (AIME) tương tự như của các bác sĩ đang hành nghề. Nghiên cứu này đã thiết lập các tiêu chuẩn phương pháp luận cho tính đại diện trong thế giới thực, tính năng mù đôi và mã hóa lỗi nghiêm ngặt. Phương pháp điều tra của chúng tôi được xây dựng trên nền tảng này. Nhưng thay vì dựa vào hàng nghìn hồ sơ bệnh nhân xác thực, không đồng nhất làm chuẩn mực, chúng tôi tập trung vào việc đánh giá các tương tác trong thế giới thực một cách minh bạch, có thể tái tạo dựa trên tốc độ nhanh chóng. Gần đây hơn, một hệ thống tiếp nhận và đề xuất AI độc quyền, không dựa trên LLM do K Health phát triển đã được đánh giá trong bối cảnh chăm sóc khẩn cấp ảo thực tế tại Cedars-Sinai. Hệ thống này thu hút bệnh nhân vào cuộc trò chuyện có cấu trúc trước khi họ đến khám qua video, đưa ra các đề xuất chẩn đoán và quản lý – bao gồm đơn thuốc, xét nghiệm và chuyển tuyến – dựa trên dữ liệu đầu vào về triệu chứng và dữ liệu EHR. Trong một nghiên cứu hồi cứu trên 461 bệnh nhân trưởng thành có các triệu chứng hô hấp, tiết niệu, âm đạo, mắt hoặc răng, các khuyến nghị của AI và bác sĩ lâm sàng phù hợp trong 56,8% trường hợp. Các chuyên gia đánh giá khuyến nghị của AI là tối ưu thường xuyên hơn so với khuyến nghị của bác sĩ lâm sàng (77,1% so với 67,1%) và AI vượt trội hơn bác sĩ lâm sàng về việc tuân thủ hướng dẫn và nhận biết các dấu hiệu cảnh báo.
Trí tuệ nhân tạo (AI) có tiềm năng giúp giảm bớt những vấn đề này. Tuy nhiên, chưa có hệ thống AI tự động đầu cuối nào dựa trên mô hình ngôn ngữ lớn (large language model LLM) được đánh giá nghiêm ngặt trong thực hành lâm sàng thực tế. Trong nghiên cứu này, chúng tôi đã đánh giá liệu một khuôn khổ AI dựa trên LLM đa tác nhân có thể hoạt động độc lập như một bác sĩ AI trong môi trường chăm sóc cấp cứu ảo hay không.
Những câu hỏi cốt lõi vẫn còn đó. Liệu một khuôn khổ đa tác nhân sử dụng LLM và các mô hình nền tảng có thể hoạt động như một bác sĩ AI hay không? Cụ thể, liệu nó có thể thực hiện tất cả các nhiệm vụ cần thiết để hoạt động tự chủ, bao gồm ghi chép bệnh sử, tổng hợp thông tin bệnh nhân bằng phương pháp đàm thoại, lập luận lâm sàng, quản lý phù hợp với hướng dẫn và lập hồ sơ chi tiết, tất cả mà không cần sự can thiệp trực tiếp của con người hay không? Liệu một bác sĩ AI hoàn toàn tự động có thể thực hiện an toàn các nhiệm vụ lâm sàng phức tạp và tinh tế này trong môi trường thực tế hay không? Điểm mạnh, điểm yếu và rủi ro của việc ra quyết định do AI điều khiển so với quyết định của bác sĩ lâm sàng trong môi trường thực tế là gì? Làm thế nào để chúng ta đảm bảo chuẩn mực mạnh mẽ, an toàn vận hành, tính minh bạch và khả năng tái tạo khi các hệ thống như vậy chuyển từ phòng thí nghiệm sang các cuộc gặp gỡ bệnh nhân?
Để trả lời những câu hỏi này, chúng tôi đã so sánh chặt chẽ Doctronic, một hệ thống lập luận và lập hồ sơ lâm sàng độc quyền, đa tác nhân, dựa trên LLM, với các bác sĩ lâm sàng giàu kinh nghiệm trong các cuộc gặp gỡ chăm sóc khẩn cấp ảo ngoài đời thực. Sử dụng phương pháp đánh giá dựa trên chuyên gia mù và LLM, phân loại lỗi rõ ràng và khuôn khổ khả năng tái tạo mạnh mẽ, chúng tôi đã đánh giá (1) sự phù hợp và an toàn của chẩn đoán; (2) việc tuân thủ các hướng dẫn quản lý; (3) độ sâu, tính rõ ràng và tính nhất quán của hồ sơ y tế; (4) tần suất, loại và mức độ rủi ro của các lỗi lâm sàng tập trung vào ảo giác; và (5) khả năng khái quát hóa và các tác động về mặt hoạt động đối với lực lượng lao động và công bằng trong chăm sóc sức khỏe.
Chúng tôi đã thử nghiệm ba giả thuyết:
(1) rằng các quyết định chẩn đoán/điều trị của AI phù hợp với các quyết định của bác sĩ lâm sàng được hội đồng chứng nhận khi đánh giá cùng một bệnh nhân và các tình huống lâm sàng;
(2) rằng tài liệu do AI điều khiển có thể cải thiện tính nhất quán và hiệu quả, với ảo giác thực tế tối thiểu;
và (3) rằng các lỗi lâm sàng lớn do tác nhân AI gây ra có thể được giảm xuống gần bằng không với kiến trúc và cơ sở phù hợp
Phương pháp
Các tác giả đã so sánh hồi cứu hiệu suất của hệ thống AI đa tác nhân Doctronic và các bác sĩ lâm sàng có giấy phép hành nghề trong 500 cuộc khám khẩn cấp từ xa liên tiếp.
Các điểm cuối chính: sự phù hợp về chẩn đoán, tính nhất quán của kế hoạch điều trị và các chỉ số an toàn, được đánh giá bằng phương pháp phân xử mù đôi dựa trên LLM và đánh giá của chuyên gia.
🌐Doctronic
Doctronic là một hệ thống mô-đun gốc đám mây, có hơn 100 tác nhân được hỗ trợ bởi LLM, mỗi tác nhân có một vai trò lâm sàng riêng biệt, được xác định rõ ràng, phản ánh trách nhiệm có cấu trúc của một đội ngũ chăm sóc sức khỏe. Các tác nhân này hoạt động phối hợp, truyền dữ liệu giàu ngữ cảnh cho nhau một cách linh hoạt. Toàn bộ hệ thống được thiết kế để mô phỏng các nhiệm vụ lâm sàng của phòng khám bác sĩ chăm sóc sức khỏe ban đầu. Trong bối cảnh này, Doctronic có khả năng thực hiện một bệnh sử đầy đủ, sau đó tạo ra một ghi chú SOAP với các thành phần sau: 1) tóm tắt HPI bao gồm các phát hiện lâm sàng tự báo cáo và các xét nghiệm chẩn đoán, 2) chẩn đoán phân biệt với ít nhất 4 chẩn đoán, 3) Kế hoạch đánh giá chẩn đoán và điều trị bổ sung dựa trên chẩn đoán phân biệt. Đối với bệnh nhân, trải nghiệm này tương tự như một cuộc trò chuyện hai chiều, mở, dựa trên văn bản. Dân số bệnh nhân và lựa chọn ca bệnh
Các ca bệnh được lấy từ các cuộc gặp gỡ y tế từ xa thông thường, không khẩn cấp tại Hoa Kỳ. Nhóm nghiên cứu có sự không đồng nhất về mặt nhân khẩu học và lâm sàng, phản ánh sự pha trộn phổ biến của các ca bệnh cấp cứu hiện đại, bao gồm các bệnh lý hô hấp cấp tính, da liễu, cơ xương khớp và tiêu hóa cũng như các bệnh nhiễm trùng. Các bản ghi chép bệnh nhân đã được ẩn danh, bao gồm nhật ký trò chuyện AI và tài liệu và kế hoạch điều trị do AI và bác sĩ lâm sàng tạo ra, được sử dụng làm dữ liệu đầu vào. Các tiêu chí loại trừ bao gồm bản ghi chép không đầy đủ, các cuộc gặp gỡ trùng lặp hoặc thiếu cả ghi chú của AI và bác sĩ lâm sàng cho cùng một cuộc gặp gỡ.
🌏Bác sĩ lâm sàng
Hiệu suất của Doctronic được so sánh với hiệu suất của các bác sĩ lâm sàng được hội đồng chứng nhận, được cấp phép tại Hoa Kỳ, chuyên về y tế từ xa. Điều này bao gồm các bác sĩ và các nhân viên y tế được đào tạo phù hợp. Các bác sĩ lâm sàng đã được đào tạo về hệ thống Doctronic trước khi nghiên cứu. Các bác sĩ lâm sàng đã được cung cấp một bản sao tài liệu do AI tạo ra trước khi họ đến khám bệnh từ xa với bệnh nhân. Các buổi gặp gỡ lâm sàng qua video tuân theo các giao thức y tế từ xa tiêu chuẩn, cho phép bác sĩ lâm sàng thu thập thêm nhiều hay ít thông tin tùy theo nhu cầu. Các ghi chú SOAP (chủ quan, khách quan, đánh giá và kế hoạch) được sử dụng để đánh giá mù đôi.
Đánh giá bởi Chuyên gia Con người
Mỗi cặp gặp gỡ mà chẩn đoán hàng đầu của AI và bác sĩ lâm sàng không khớp nhau sẽ được đánh giá bởi một bác sĩ được hội đồng chứng nhận có quyền truy cập vào tài liệu tham khảo y khoa. Việc che giấu nguồn gốc của tài liệu cho bác sĩ tỏ ra không thực tế, vì các ghi chú dựa trên AI rất nhất quán và do đó dễ dàng nhận ra trong một vài cặp. Bác sĩ được yêu cầu xác định nguyên nhân của sự bất đồng giữa các tài liệu, liệu AI hay bác sĩ có nhiều khả năng đúng hơn, liệu không thể xác định chẩn đoán nào phù hợp hơn, và liệu các chẩn đoán có thực sự khớp nhau hay không.
Kết quả
Để định lượng mức độ tương đồng giữa ghi chú SOAP do AI tạo ra và do bác sĩ lâm sàng biên soạn, chúng tôi đã áp dụng ba phép đo dựa trên văn bản bổ sung, mỗi phép đo phản ánh các khía cạnh khác nhau của độ tương đồng bề mặt (Bảng 3). Độ tương đồng cosine TF-IDF đánh giá tầm quan trọng của các từ được sử dụng. Tần suất thuật ngữ (TF) đo lường tần suất xuất hiện của mỗi từ trong một ghi chú. Tần suất tài liệu nghịch đảo (IDF) làm giảm ảnh hưởng của các từ phổ biến trong toàn bộ tập dữ liệu, nhấn mạnh những từ đặc trưng cho từng ghi chú, làm nổi bật mức độ mà cả hai.
Các ghi chú có cùng một mô hình các từ quan trọng, đặc trưng. Điểm TF-IDF trung bình thấp (trung bình 0,2285 ± 0,084), cho thấy ghi chú của AI và con người nhìn chung khác nhau về các đặc điểm ngôn ngữ chính.
Chỉ số Jaccard, đánh giá tỷ lệ các từ duy nhất được chia sẻ giữa các ghi chú, cũng thấp (trung bình 0,087 ± 0,045), cho thấy trung bình, chưa đến 9% số từ trong một cặp ghi chú thông thường được chia sẻ. Do đó, sự trùng lặp về vốn từ vựng giữa tác giả AI và con người là rất nhỏ.
Tỷ lệ Levenshtein, đo lường mức độ tương đồng ở cấp độ ký tự dựa trên số lần chỉnh sửa tối thiểu cần thiết để chuyển đổi một ghi chú thành ghi chú khác, cũng khá thấp (0,364 ± 0,054), cho thấy mức độ tương đồng cao hơn một chút so với các số liệu ở cấp độ từ, nhưng vẫn phản ánh sự khác biệt đáng kể về cách diễn đạt và định dạng. Nói cách khác, mặc dù ghi lại các trường hợp lâm sàng giống nhau, các ghi chú do AI và bác sĩ lâm sàng tạo ra thường khác nhau về các chi tiết cụ thể về cách diễn đạt và cấu trúc.
Ngược lại, độ tương đồng cosin dựa trên nhúng, nắm bắt các mối quan hệ ngữ nghĩa cấp cao hơn, mang lại điểm số cao hơn đáng kể. Do đó, bất chấp những khác biệt về phong cách và từ vựng, các ghi chú cho thấy độ tương đồng ngữ nghĩa cao khi được đo bằng nhúng.
Những kết quả này chỉ ra rằng mặc dù ghi chú Doctronic và ghi chú do con người viết thường khác nhau về cách diễn đạt và cấu trúc chính xác, nhưng chúng nhất quán về mặt ngữ nghĩa trong việc ghi chép lý luận lâm sàng, đánh giá và kế hoạch điều trị. Mô hình này hỗ trợ tiềm năng của tài liệu do AI tạo ra để phản ánh chính xác ý định và nội dung của ghi chú y tế do con người viết, ngay cả khi các biểu thức bề mặt khác nhau.
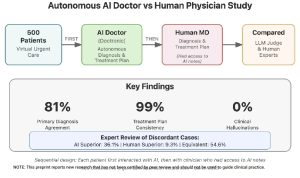
🍀Chẩn đoán hàng đầu của Doctronic và bác sĩ lâm sàng khớp nhau trong 81% trường hợp, và kế hoạch điều trị khớp nhau trong 99,2% trường hợp. 🍀Không xảy ra ảo giác lâm sàng (ví dụ: chẩn đoán hoặc điều trị không được hỗ trợ bởi các phát hiện lâm sàng).
🍀Trong đánh giá của chuyên gia về các trường hợp không khớp nhau, hiệu suất của AI vượt trội hơn ở 36,1% và hiệu suất của con người vượt trội hơn ở 9,3%; các chẩn đoán tương đương nhau trong các trường hợp còn lại.
🍀Thảo luận
Trong nghiên cứu này, là minh chứng thực tế sâu rộng nhất về một bác sĩ AI tự động, đa tác nhân, chúng tôi đã so sánh hiệu suất của Doctronic với các bác sĩ lâm sàng được chứng nhận bởi hội đồng quản trị trong 500 cuộc gặp gỡ chăm sóc sức khỏe từ xa khẩn cấp liên tiếp. Phát hiện của chúng tôi đã xác nhận cả ba giả thuyết:
(1) các quyết định chẩn đoán và điều trị của AI nhất quán với các quyết định của các bác sĩ lâm sàng được chứng nhận bởi hội đồng quản trị khi đánh giá cùng một bệnh nhân và các tình huống lâm sàng;
(2) tài liệu do AI điều khiển có thể cải thiện tính nhất quán và hiệu quả, với ảo giác thực tế tối thiểu;
và (3) các lỗi lâm sàng nghiêm trọng do tác nhân AI gây ra có thể được giảm xuống gần bằng không với kiến trúc và nền tảng phù hợp.
Cụ thể, chúng tôi nhận thấy rằng chẩn đoán hàng đầu của Doctronic và bác sĩ lâm sàng trùng khớp trong hơn 80% trường hợp, và các kế hoạch điều trị trùng khớp trong hơn 99% trường hợp. Độ tin cậy của kết quả trên các bệnh nhân, khiếu nại và phân nhóm nhân khẩu học đã được xác nhận bằng các phân tích định tính và thống kê.Trong một đánh giá chuyên môn về 97 trường hợp không thống nhất của các bác sĩ lâm sàng được hội đồng chứng nhận, hiệu suất chẩn đoán của AI được đánh giá là vượt trội trong 36,1% trường hợp, và hiệu suất của con người được đánh giá là vượt trội trong 9,3%. Trong các trường hợp còn lại, chẩn đoán hoặc mơ hồ hoặc thực tế là giống nhau nhưng được diễn đạt bằng ngôn ngữ khác biệt đáng kể. Do đó, Doctronic tốt như các bác sĩ lâm sàng giàu kinh nghiệm trong bối cảnh này và thực hiện ở mức hoặc cao hơn tiêu chuẩn của các hệ thống AI đã công bố.
Không giống như các hệ thống hỗ trợ trước đây chỉ cung cấp khuyến nghị để bác sĩ lâm sàng xem xét, Doctronic đã tự mình tiến hành đánh giá lâm sàng đầy đủ, bao gồm việc ghi chép bệnh sử, lập luận và ghi chép, mà không cần sự tham gia của con người. Phát hiện lâm sàng chính, rằng Doctronic có thể tự động đưa ra chẩn đoán chính xác và kế hoạch điều trị an toàn trong hầu hết mọi trường hợp, có ý nghĩa trực tiếp đối với khả năng tiếp cận và chất lượng chăm sóc khẩn cấp. Mặc dù các ghi chú AI đôi khi bỏ sót chi tiết theo ngữ cảnh hoặc không bao gồm các chẩn đoán phân biệt có liên quan, nhưng những thiếu sót này hầu như không bao giờ chuyển thành các kế hoạch không an toàn hoặc bỏ sót các hành động quản lý. Việc không có các sự kiện ảo giác (ví dụ: chẩn đoán/điều trị không được hỗ trợ bởi các phát hiện lâm sàng) càng phân biệt Doctronic với các LLM tài liệu cũ hơn và thậm chí cả một số người ghi chép AI lai hiện tại.
Phân tích của chúng tôi về các trường hợp không thống nhất đã mang lại những hiểu biết quan trọng về cách tốt nhất để đánh giá các hệ thống AI trong bối cảnh liên quan đến lâm sàng. Chẩn đoán y khoa thường không chắc chắn, và vai trò của bác sĩ lâm sàng, hoặc trong trường hợp này là AI, là đưa ra chẩn đoán phân biệt toàn diện và kiểm tra giả thuyết rằng một trong những chẩn đoán đó là chính xác, thông qua các xét nghiệm chẩn đoán hoặc thử nghiệm điều trị theo kinh nghiệm. Trong cả hai trường hợp, chức năng quan trọng là phát triển một kế hoạch đánh giá và điều trị phù hợp. Giống như bác sĩ lâm sàng, AI và bác sĩ lâm sàng có thể không đồng ý về chẩn đoán. Những trường hợp như vậy nên được đánh giá dựa trên sự thiên vị về tính nhất quán của kế hoạch điều trị, một thước đo được thiết kế để xác định liệu kế hoạch quản lý ban đầu có dẫn đến việc quản lý an toàn, tương tự và phù hợp trong bối cảnh không chắc chắn hay không. Theo thước đo này, Doctronic và các bác sĩ lâm sàng chuyên gia gần như hoàn toàn đồng nhất.
Phát hiện của chúng tôi cho thấy, với các biện pháp bảo vệ có cấu trúc, các hệ thống AI chủ động có thể được sử dụng tuần tự với bác sĩ lâm sàng hoặc như một công cụ tuyến đầu để tăng khả năng tiếp cận dịch vụ chăm sóc khẩn cấp, vốn thường bị trì hoãn do thiếu hụt nhân lực và thời gian chờ đợi chăm sóc y tế. Đối với các môi trường hạn chế về nguồn lực và y tế ngoài giờ, tính tự chủ ở mức độ này có thể tăng đáng kể khả năng tiếp cận và giảm thời gian chờ đợi.
Trong hệ thống y tế của các nước phát triển, lợi ích chính của AI là tăng cường thông lượng và cho phép các bác sĩ lâm sàng tập trung vào các mối quan hệ phức tạp, liên quan nhiều đến tương tác hoặc theo chiều dọc.
Hạn chế
Mặc dù việc đánh giá mù, thực tế, quy mô lớn này đối với một bác sĩ AI có nhiều ưu điểm, nhưng vẫn cần phải thừa nhận một số hạn chế. Có lẽ quan trọng nhất, nghiên cứu của chúng tôi nhằm đánh giá tính an toàn của một hệ thống tự động đa tác nhân trong bối cảnh thực tế bằng cách sử dụng sự nhất quán chứ không phải tính chính xác. Chúng tôi chọn cách tiếp cận này vì khái niệm “đúng” đôi khi còn mơ hồ. Sự thật cơ bản dựa trên kết quả theo dõi không được xem xét. Do đó, các phát hiện cho thấy sự đồng thuận chứ không phải tính chính xác. Một hạn chế khác là các ghi chú AI được cung cấp cho các bác sĩ lâm sàng trước mỗi lần khám lâm sàng, có khả năng tạo ra hiệu ứng neo đậu, có thể khiến họ thiên vị theo đánh giá dựa trên AI. Hơn nữa, các bác sĩ lâm sàng có thể thu thập thêm thông tin ngoài thông tin do AI cung cấp. Tương tự như cái gọi là “hiệu ứng tham dự”, trong đó các bác sĩ cao cấp nhận được thông tin khác biệt đáng kể so với các thực tập sinh từ cùng một bệnh nhân, các bác sĩ lâm sàng có thể đã nhận được thông tin khác nhau, làm thay đổi chẩn đoán và cách tiếp cận của họ.
Những hạn chế quan trọng khác liên quan đến nghiên cứu hiện tại về AI đa tác nhân. Thứ nhất, kết quả của chúng tôi phản ánh dịch vụ chăm sóc khẩn cấp dựa trên tiếng Anh và tiếng Hoa Kỳ và có thể không thể khái quát hóa cho những người không nói tiếng Anh và không sử dụng dịch vụ chăm sóc sức khỏe từ xa. Thứ hai, vì chúng tôi sử dụng một Thạc sĩ Luật (LLM) làm người đánh giá, với việc kiểm tra ở cấp độ con người như một biện pháp bảo vệ chống lại sự thiên vị có hệ thống, nên người đánh giá LLM có thể đã đưa ra một số mức độ sai sót. LLM làm người đánh giá là một phương pháp luận mới nổi và chưa được sử dụng rộng rãi cho đến gần đây. Việc tiếp tục sử dụng các mô hình đa dạng và người đánh giá là con người được khuyến nghị.
Trong tương lai, hiệu suất của các bác sĩ lâm sàng không có quyền truy cập vào ghi chú AI nên được đánh giá để giảm thiểu sự thiên vị neo đậu xuất hiện khi các bác sĩ lâm sàng xem xét các ghi chú do AI tạo ra trước. Các hệ thống đánh giá phức tạp hơn để đảm bảo nhiều đánh giá dựa trên số liệu sẽ rất quan trọng trong giai đoạn thử nghiệm tiếp theo. Điều này nên bao gồm việc theo dõi bệnh nhân sau khi khám để có thể sử dụng các kết quả cụ thể của bệnh nhân nhằm đánh giá hiệu quả của các kế hoạch điều trị.
Kết luận
Trong lần xác thực quy mô lớn đầu tiên này đối với một bác sĩ AI tự động, chúng tôi đã chứng minh được sự phù hợp mạnh mẽ giữa chẩn đoán và kế hoạch điều trị với các bác sĩ lâm sàng. Những phát hiện này cho thấy các hệ thống AI đa tác nhân có thể đạt được khả năng ra quyết định lâm sàng tương đương với các nhà cung cấp dịch vụ y tế và mang đến một giải pháp tiềm năng cho tình trạng thiếu hụt nhân lực y tế.
Nguồn doi: https://doi.org/10.1101/2025.07.14.25331406