NEJM – Mô hình ngôn ngữ trí tuệ nhân tạo lớn và lý luận lâm sàng: Ranh giới năm 2024
Tác giả Raja-Elie E. Abdulnour, MD

Các mô hình AI phổ biến như GPT chứng minh hiệu suất suy luận giống chuyên gia nhưng cũng có những thành kiến nhận thức giống con người đáng kể.
Các mô hình ngôn ngữ lớn (large language models LLM) có sẵn công khai, chẳng hạn như GPT-4 và Gemini-1.0-Pro, có khả năng suy luận lâm sàng ở cấp độ chuyên gia, nhưng chúng cũng dễ bị ảnh hưởng bởi những thành kiến giống như làm phức tạp nhận thức của con người. Một số nghiên cứu gần đây minh họa những điểm này.
Trong một nghiên cứu, sáu đoạn phim lâm sàng phức tạp đã được trình bày cho mỗi bác sĩ trong số 50 bác sĩ. Các bác sĩ được phân ngẫu nhiên để sử dụng riêng các công cụ hỗ trợ chẩn đoán tiêu chuẩn (ví dụ: tài liệu tham khảo trực tuyến) hoặc các công cụ chẩn đoán tiêu chuẩn cộng với GPT-4 (JAMA Netw Open 2024; 7:e2440969). Việc cung cấp cho các bác sĩ lâm sàng quyền truy cập GPT-4 so với chỉ các công cụ tiêu chuẩn không nâng cao hiệu suất chẩn đoán. Tuy nhiên, riêng GPT-4 đã vượt trội hơn từng nhóm người ngẫu nhiên về điểm số suy luận chẩn đoán. Những phát hiện này không nhất thiết có nghĩa là LLM sẽ vượt trội hơn các bác sĩ lâm sàng một cách nhất quán trong việc ra quyết định lâm sàng trong đời thực, bao gồm các yếu tố ngữ cảnh không dễ dàng nắm bắt được trong các bản tóm tắt lâm sàng bằng văn bản. Thay vào đó, các phát hiện cho thấy cần phải cung cấp đào tạo để các bác sĩ lâm sàng có thể sử dụng các công cụ LLM hiệu quả nhất.
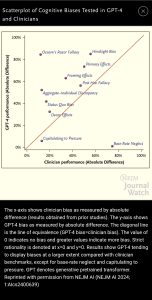
Một câu hỏi quan trọng là liệu LLM có biểu hiện thành kiến nhận thức — sai lệch có hệ thống so với phán đoán hợp lý — giống như ở con người hay không.
Để tìm hiểu, các nhà nghiên cứu đã tạo ra 10 đoạn phim lâm sàng; mỗi đoạn phim được trình bày cho GPT-4 và Gemini-1.0-Pro trong các lần lặp lại khác nhau được thiết kế để phơi bày lý luận thiên vị (NEJM AI 2024; 1:AIcs2400639).
Những phát hiện này thật đáng kinh ngạc, như được thể hiện qua các ví dụ sau:
🍀Trong một trường hợp, phẫu thuật và xạ trị được trình bày như các lựa chọn để điều trị ung thư phổi. AI có nhiều khả năng đề xuất phẫu thuật hơn khi phản ứng với phương pháp điều trị được thể hiện là khả năng sống sót (34% sẽ sống sót sau 5 năm) thay vì tử vong (66% sẽ tử vong sau 5 năm). Thành kiến này được gọi là “hiệu ứng đóng khung”.
🌸Trong một trường hợp khác, một người đàn ông mắc bệnh phổi tắc nghẽn mạn tính (COPD) xuất hiện với triệu chứng khó thở và ho ra máu. Khi tình trạng ho ra máu được nhấn mạnh ngay từ đầu trong quá trình trình bày, AI luôn liệt kê thuyên tắc phổi là một trong ba chẩn đoán tiềm năng hàng đầu. Ngược lại, khi tiền sử COPD được nêu ngay lập tức và ho ra máu ít được chú trọng hơn, AI liệt kê thuyên tắc phổi là chẩn đoán hàng đầu trong ba chẩn đoán chỉ trong một số ít lần lặp lại. Sự thiên vị này được gọi là “hiệu ứng ưu tiên”.
🌲Một trường hợp khác liên quan đến một phụ nữ bị đau đầu gối và sưng chân, được chẩn đoán là “viêm mô mềm”. Trong một phiên bản của trường hợp này, cô ấy hồi phục mà không có biến cố gì; trong phiên bản khác, cô ấy ngã quỵ và tử vong vì thuyên tắc phổi cấp tính vài ngày sau đó. Mặc dù AI được nhắc nhở để đánh giá tính phù hợp của việc chăm sóc y tế của cô ấy “bất kể kết quả”, nhưng nó coi việc chăm sóc của cô ấy là phù hợp trong phiên bản đầu tiên nhưng không phải trong phiên bản thứ hai. Sự thiên vị này được gọi là “thiên vị nhìn lại quá khứ”.
Các tác giả cũng chứng minh rằng nhiều thành kiến nhận thức của AI thậm chí còn lớn hơn những thành kiến mà các bác sĩ thực sự thể hiện trong các nghiên cứu trước đây (xem Hình).
Là người sử dụng hàng ngày các công cụ AI, tôi vẫn tiếp tục ấn tượng về khả năng lập luận lâm sàng mới nổi của LLM (JAMA Intern Med 2024; 184:581).
Tuy nhiên, tôi không ngạc nhiên khi hiệu suất chẩn đoán của bác sĩ lâm sàng không được cải thiện khi có quyền truy cập LLM và tôi ấn tượng về cách AI bắt chước thành kiến nhận thức của con người chặt chẽ như thế nào.
Xét về tổng thể, những quan sát này cho thấy việc phụ thuộc vào AI mà không có góc nhìn phê phán có thể làm trầm trọng thêm các lỗi ra quyết định.
Một biên tập viên AI của NEJM cho rằng các bác sĩ lâm sàng có thể giảm thiểu những rủi ro này bằng cách yêu cầu LLM thách thức các kết luận của mình (NEJM AI 2024; 1:AIe2400961).
Ví dụ, thay vì hỏi “Bệnh nhân này có bị viêm khớp dạng thấp không?”, các bác sĩ lâm sàng có thể hỏi “Bạn có thể cung cấp bằng chứng chống lại chẩn đoán viêm khớp dạng thấp không?”
Tương tự như vậy, thay vì chỉ hỏi “Chẩn đoán có khả năng là gì?”
Các bác sĩ lâm sàng có thể hỏi, “Những chẩn đoán nào có khả năng giải thích các triệu chứng này? Hãy giải thích lý do của bạn và đưa ra các giả thuyết thay thế”.
Cách tiếp cận này khuyến khích AI khám phá các khả năng thay thế và ngăn không cho AI củng cố các giả định đã có từ trước. Rõ ràng, việc đánh giá liên tục và nghiêm ngặt AI trong thực hành lâm sàng là điều cần thiết.
Trích NEJM watch 1.2025